2025-10-04 11:29 Tags:
Linear Regression — Gradients and Gradient Descent
1. Cost Function Reminder
We use Mean Squared Error (MSE):
where:
- = number of samples
- = true value
- (prediction from our model)
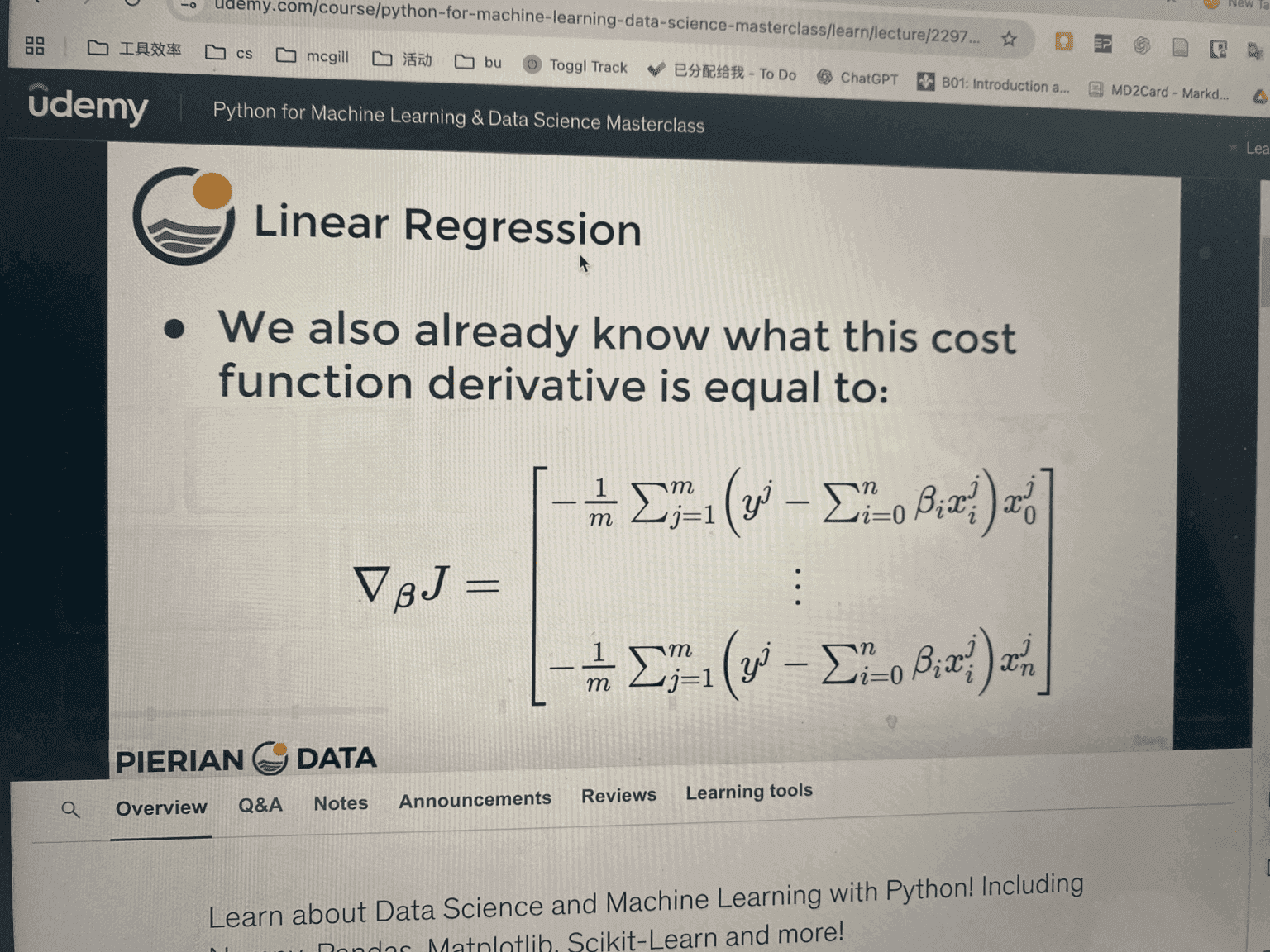
2. Take Derivative (Gradient)
We want to minimize , so we take derivatives.
For one parameter :
- This tells us how sensitive the cost is to changing .
- If derivative is positive → cost increases as grows.
- If derivative is negative → cost decreases as grows.
3. Gradient Vector
Instead of doing one parameter at a time, we collect all derivatives:
This is called the gradient.
It points in the direction of steepest increase of the cost.
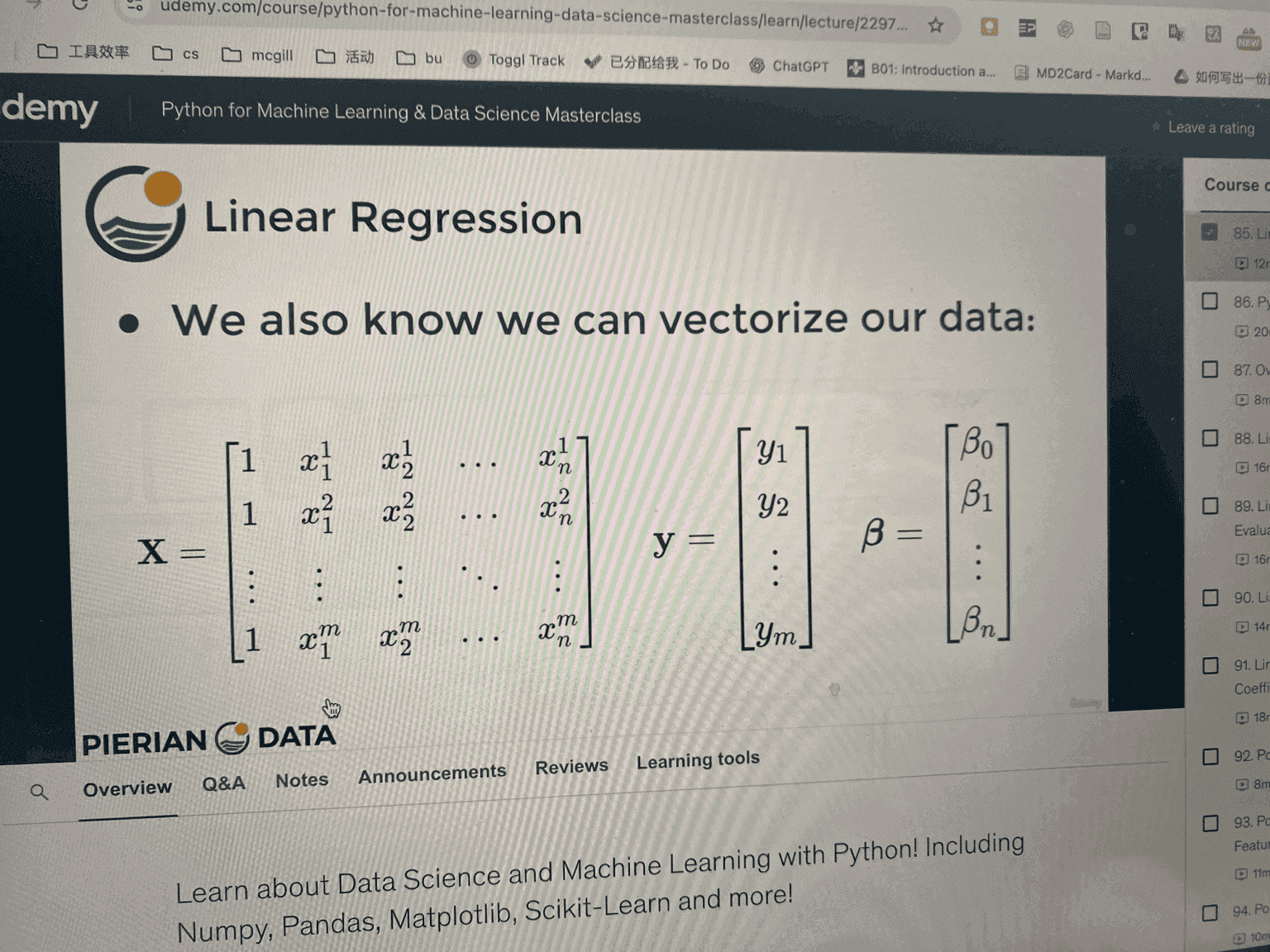

4. Matrix Form (Vectorization)
We can rewrite using matrices:
- = feature matrix (size , with 1’s column for intercept)
- = vector of actual outputs ()
- = vector of parameters ()
Prediction:
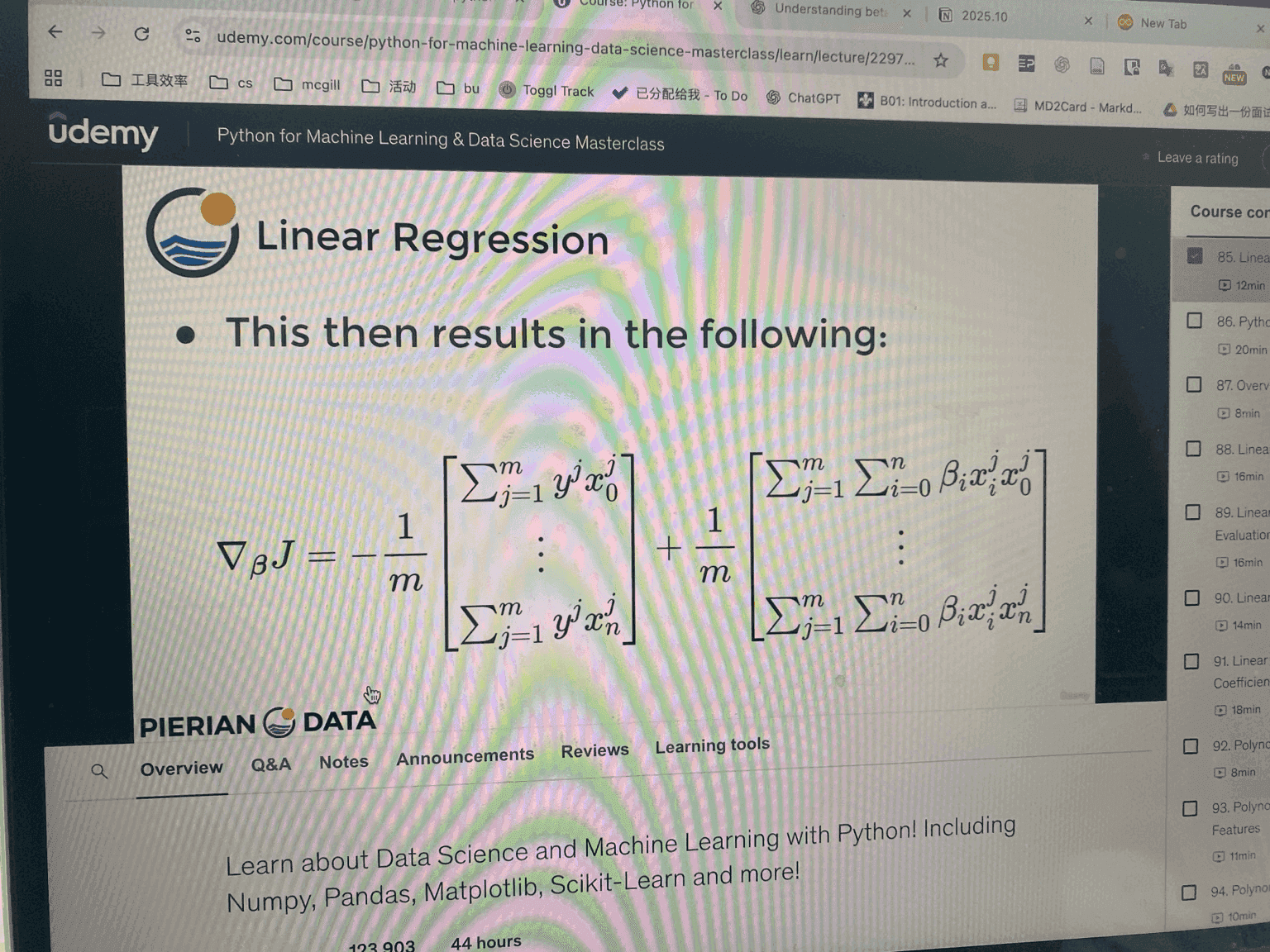
Gradient:
This is a compact and efficient way to compute the gradient.
5. Gradient Descent Update Rule
We iteratively update:
- = learning rate (step size).
- We keep moving in the opposite direction of the gradient until convergence.
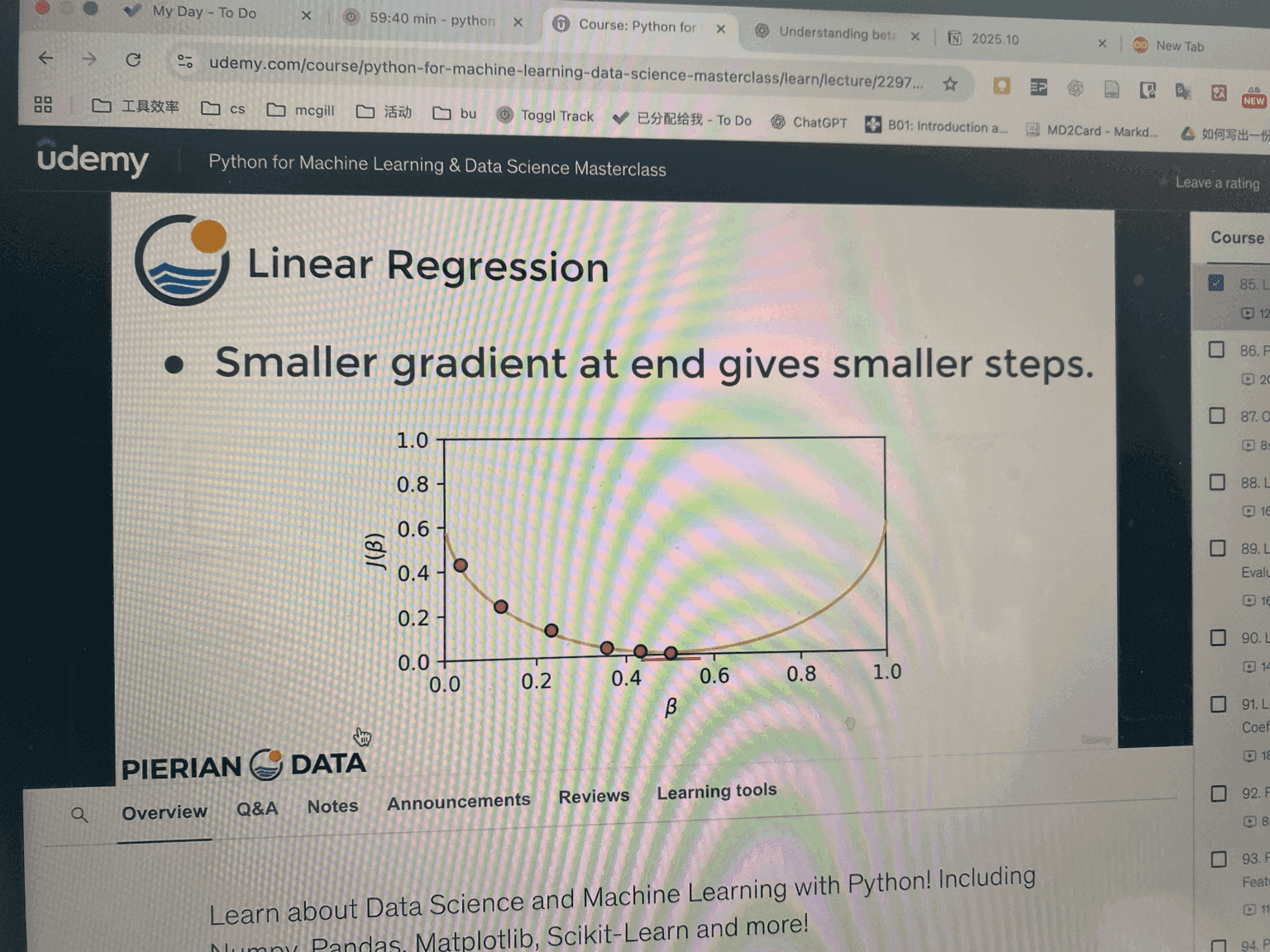
6. Intuition (Why Steps Change Size)
-
At the start:
Gradient is large → big steps downhill. -
Near the minimum:
Gradient is small → smaller, finer steps.
So the algorithm naturally slows down as it gets closer to the best solution.
7. Algorithm Process
- Initialize randomly (or zeros).
- Compute gradient .
- Update .
- Repeat until convergence (cost stops decreasing).