2026-04-16 11:31 Tags:
🧠 1. What is Gini impurity (intuition)?
👉 Gini impurity measures:
“How mixed a group is”
Think like this:
You randomly pick one sample from a group.
👉 Gini = probability that you misclassify it
Examples
Case 1: perfectly pure
[Fraud, Fraud, Fraud, Fraud]👉 Gini = 0
✔️ no confusion
✔️ perfect
Case 2: very mixed
[Fraud, Legit, Fraud, Legit]👉 Gini = high (~0.5)
❌ very confusing
👉 So:
| Situation | Gini |
|---|---|
| pure | 0 |
| mixed | high |
🔢 2. The formula

We want to minimize the gini impurity in the leaf node
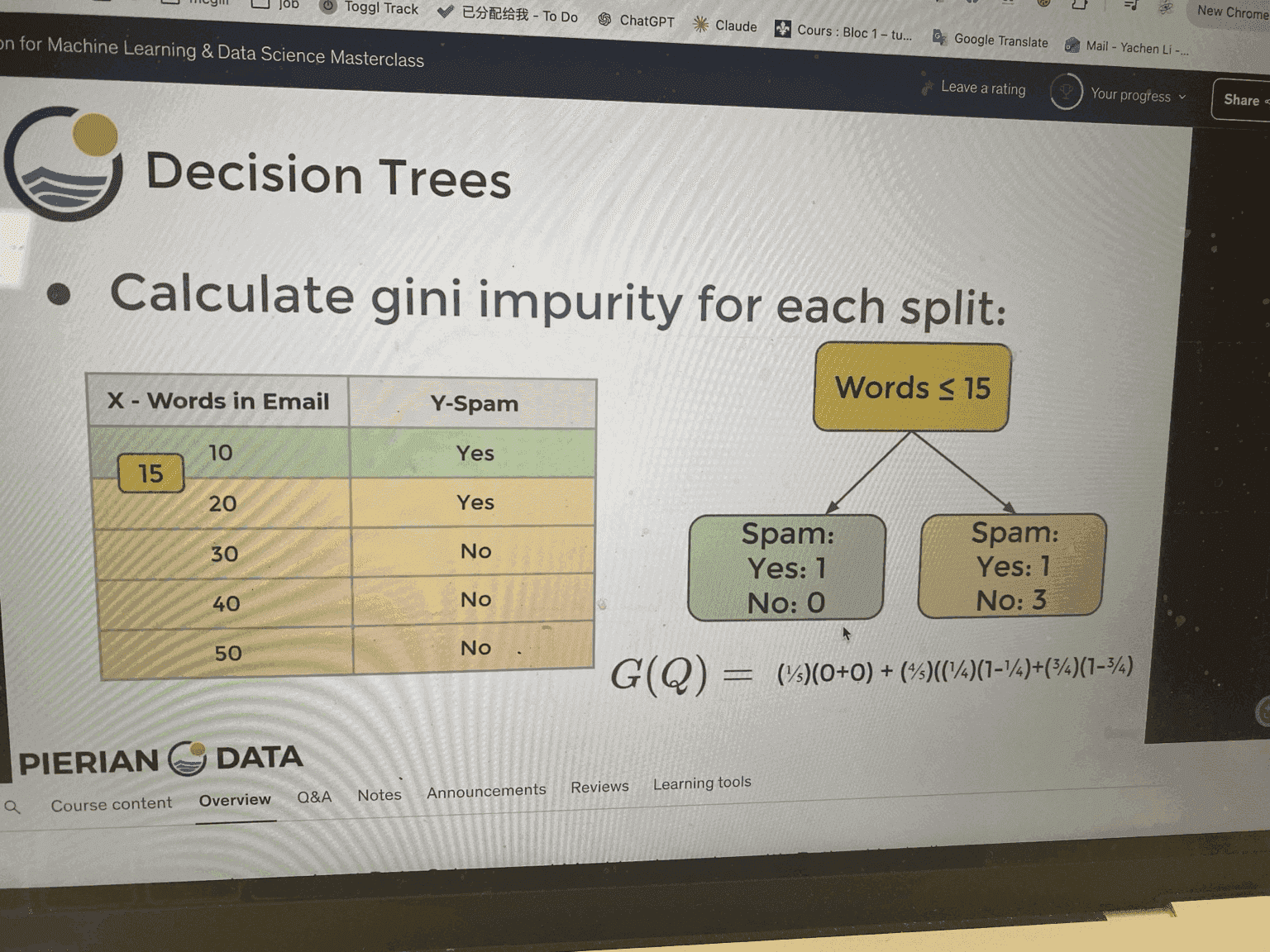
Left node (≤15)
Only one sample:
-
Yes = 1
-
No = 0
👉 Pure node
So:
Right node (>15)
Data:
| Words | Spam |
|---|---|
| 20 | Yes |
| 30 | No |
| 40 | No |
| 50 | No |
Counts:
-
Yes = 1
-
No = 3
Probabilities:
-
(p_{yes} = 1/4)
-
(p_{no} = 3/4)
⚖️ Step 5: Why do we weight them?
This is the part you’re asking: “why calculate like this?”
Because:
👉 The two groups are NOT the same size
-
Left node: 1 sample
-
Right node: 4 samples
So we do a weighted average:
🔥 The real intuition (this is what matters)
Forget the formula for a second. Think like this:
🎯 A good split should:
-
Make groups more pure
-
Especially make the large group pure
💡 Why weighting?
Because:
A mistake in a big group matters more than a mistake in a small group
🧠 One deeper insight (this is how pros think)
Decision trees are basically doing:
👉 “Try all possible splits”
👉 “Pick the one with lowest Gini”
🚀 Quick check for you
Try this mentally:
👉 What if the split was Words ≤ 25?
-
Left: (10, 20) → both Yes
-
Right: (30, 40, 50) → all No
What would the Gini be?
(If you get this, you’ve basically mastered the concept.)
